Let’s assume you already know about Wordle. As you may know, Wordle uses a curated list of five-letter words. For example, it doesn’t include plurals of four-letter nouns (no BOOKS) or past tenses ending in ED (no TIMED). The list is easily discoverable online, at least I discovered one and maybe it’s the one used in the puzzle. You can see it in this CODAP document.
But this blog is about data, so that’s where we’re going. You know from growing up with (or learning) English that E is the most common letter. You might even remember a mnemonic such is ETAOIN SHRDLU that’s supposed to represent the top dozen letters by frequency. I once learned ETAONRISH for the same purpose. These listings are not the same! How could that be?
Read more: Letter Frequencies (and more) in WordleOf course, it’s because they must have been compiled from different sources of text. Consider: suppose Blanziflor uses the words in a dictionary, while Helena uses the text of today’s New York Times. Helena might have more T, H, and E than Blanziflor simply because THE appears many times in her text but only once in Blanziflor’s.
So it might be interesting to look at letter frequencies in the “Wordle corpus,” if only to get an idea of which letters to try to fit into your next guess.
So, for your exploration and enjoyment, here is a CODAP document (same link as above) with “my” Wordle list, broken down into individual letters using the “texty” plugin.
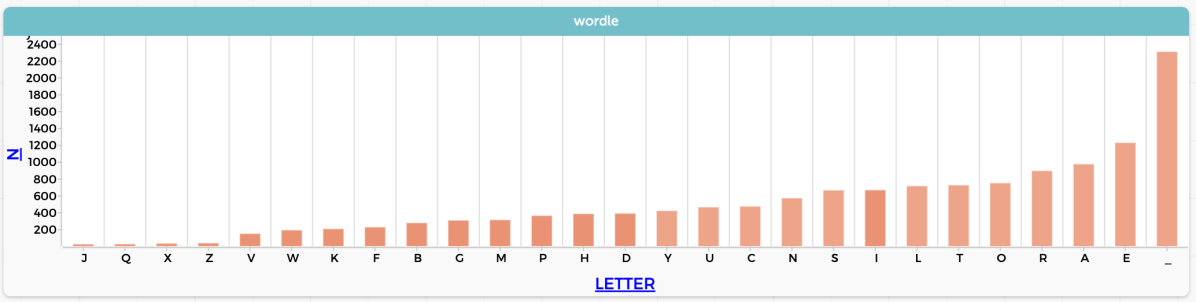
I get EAROT LISNC UY for the top twelve. See the graph at the top of this post.
To make that graph in CODAP, I grouped the data by letter, then made a new attribute to count() the number of appearances of each letter. That’s kind of an “intermediate” CODAP task with very little explanation; see if you can figure out how to do it.
The analysis also includes digraphs, that is, all the two-letter sequences, with the underscore “_” standing in for a space. So in the table below you see r_ (case 6) containing the last letter in CIGAR and _r (case 7) with the first letter in REBUT.

An interesting question here might be something like, “J is the least common letter. How many times does it appear? Is it always the first letter of the word?”
One more thing: is this cheating? Reasonable people can disagree; here’s how I draw that line: writing a version of WordleBot for personal use is an interesting programming challenge, but would be cheating for actually doing Wordle. Searching the word list using regular expressions is a no-no for sure. I think that looking at the word list while doing Wordle is still cheating, at least a little. But having looked at the word list is OK. Likewise, learning the frequencies of letters, I think, is OK: it’s enhanced common sense. It does not use the power of computing to be systematic and exhaustive.