Welcome to the third in a soon-to-end series in which I figure out what I think about time series data, and how it is different from the data we usually encounter in school assignments. We’re exploring what tools and techniques we might use with time series that we don’t traditionally cover in stats or science, and wondering whether maybe we should. For me and my CODAP buddies, it also raises the question of whether a tool like CODAP should have more built-in support for time series.
Smoothing
One of these tools is smoothing. There is smoothing (for example Loess smoothing) for other, non-function-y data, but smoothing is easier to understand with time series (or any other data that’s fundamentally a function; the previous post in this series explains this obsession with functions).
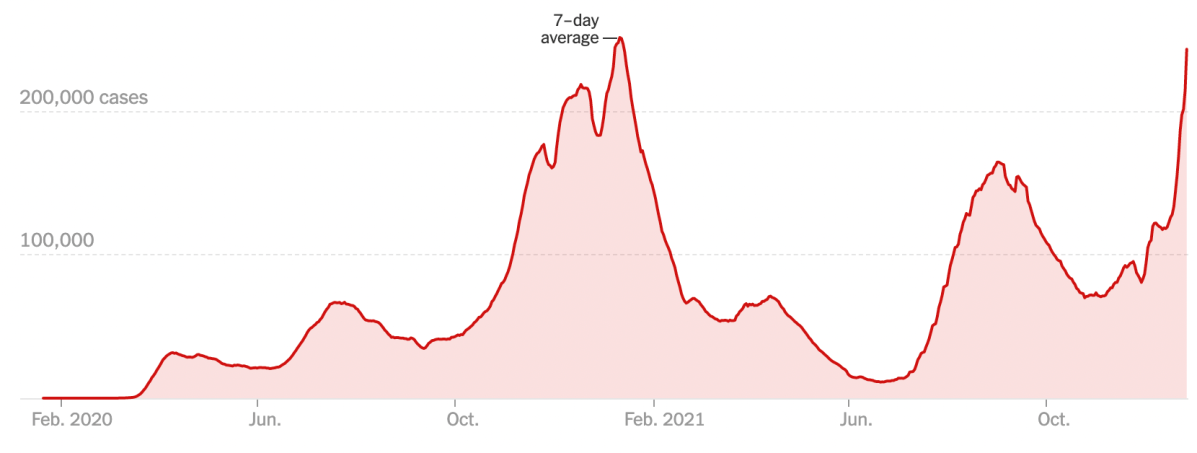
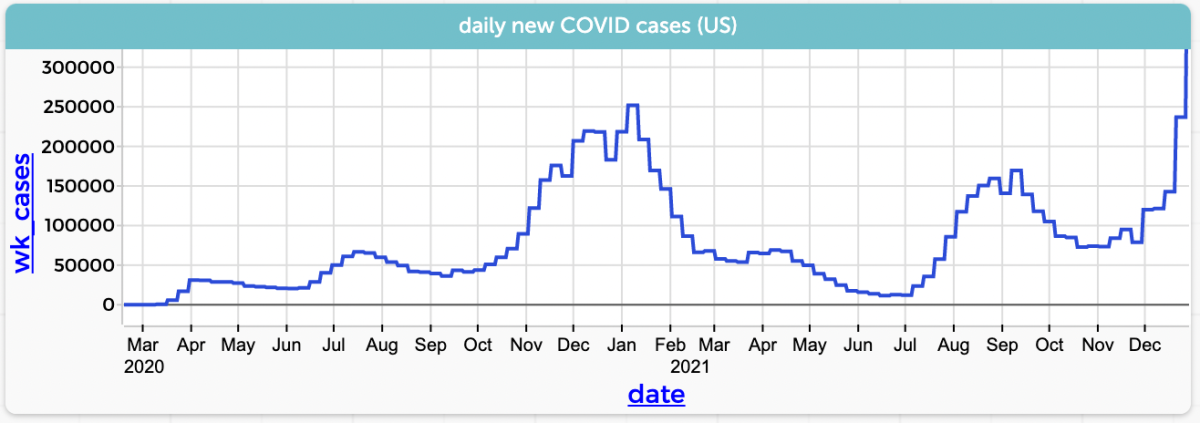
Since it’s December 2021, let’s stick with COVID and look at the number of new cases in the US by day (CODAP file here):

Graph in CODAP